




Prosta baza danych to praktyczne narzędzie wspierające monitoring, ewaluację oraz proces uczenia się. Umożliwia określenie liczby osób objętych poszczególnymi działaniami i całym projektem, a także pozwala na łączenie, grupowanie, analizę i wizualizację zebranych informacji. Ze względu na swoją prostotę i niskie koszty organizacje pozarządowe najczęściej korzystają z nieskomplikowanych baz tworzonych w programie Excel.
Informacje o uczestnikach projektu — zarówno objętych wsparciem bezpośrednim, jak i pośrednim — w tym ich liczba oraz kluczowe cechy, są niezbędne do podejmowania decyzji zarządczych, prowadzenia sprawozdawczości oraz zapewnienia rozliczalności działań. Dobrą praktyką jest gromadzenie dla każdego uczestnika co najmniej danych w podziale na płeć i wiek (Sex, Age Disaggregated Data – SADD). W zależności od charakteru wsparcia baza może zawierać także informacje o przynależności do grup wrażliwych, rodzaju interwencji, lokalizacji czy dane kontaktowe.
Co oznacza zliczanie uczestników projektu
Zliczanie unikalnych beneficjentów
Donatorzy zazwyczaj wymagają raportowania liczby bezpośrednich beneficjentów dla poszczególnych działań oraz łącznej liczby unikalnych osób objętych wsparciem, przy czym każda osoba powinna być liczona tylko raz. W praktyce oznacza to, że ta sama osoba może uczestniczyć w różnych działaniach (np. korzystać z pomocy prawnej i brać udział w szkoleniach), jednak przy prezentowaniu łącznej liczby beneficjentów konieczne jest usunięcie duplikatów. Zadanie to najczęściej realizuje zespół ds. monitoringu i ewaluacji (poniżej opisano, jak zrobić to w programie Excel).
W niektórych przypadkach nie ma potrzeby indywidualnego rejestrowania beneficjentów. Dotyczy to zwłaszcza działań infrastrukturalnych — na przykład gdy organizacja buduje studnię dla danej społeczności, liczbę osób objętych wsparciem określa się na podstawie liczby jej mieszkańców. Dane te zazwyczaj pochodzą z oficjalnych lub publicznie dostępnych źródeł statystycznych. Szczegółowe wytyczne dotyczące metod liczenia uczestników można znaleźć tutaj: WFP, USG, Women Peace Fund, Oxfam.
Rozbicie danych (ang. data disaggregation)
Dezagregacja danych polega na gromadzeniu informacji o kluczowych cechach uczestników oraz na możliwości ich analizy i zliczania według tych cech. Przykładowo, na podstawie zestawu danych można określić, że w danej grupie są 3 osoby, w tym 2 mężczyzn i 1 kobieta (czyli dane w podziale na płeć i wiek).
W praktyce organizacje pozarządowe często napotykają trudności wynikające z różnic w wymaganiach donatorów dotyczących dezagregacji danych:
- zakres zbieranych informacji może się różnić — od podstawowych danych SADD po bardziej szczegółowe dane, np. dotyczące podatności na zagrożenia, dochodów czy poziomu wykształcenia;
- stosowane definicje kategorii bywają odmienne — np. niepełnosprawność może być określana na podstawie kwestionariusza Washington Group lub oficjalnego orzeczenia;
- różnice mogą dotyczyć także sposobu grupowania danych — np. inne przedziały wiekowe (0–5 lat vs. 0–3 i 4–6 lat).
Dlatego kluczowe jest jednoznaczne ustalenie zasad dezagregacji danych już na etapie projektowania systemu monitoringu i ewaluacji.
Określanie liczby beneficjentów pośrednich
Do beneficjentów pośrednich zalicza się najczęściej:
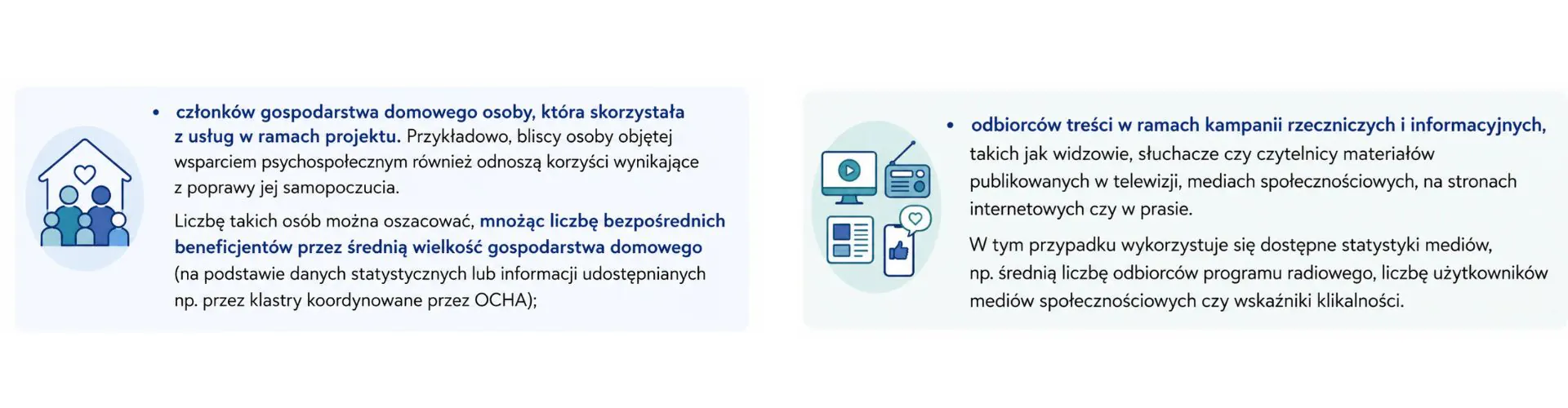
Wskazówki – przydatne funkcje w programie Excel
- Tworzenie unikalnych kodów beneficjentów w celu wyeliminowania zduplikowanych wpisów
Aby wyodrębnić z listy wyłącznie niepowtarzające się (unikalne) osoby, stosuje się proces deduplikacji. Wymaga on przypisania każdemu beneficjentowi unikalnego identyfikatora. Może to być numer nadany przez organy państwowe (np. numer dowodu osobistego, paszportu czy PESEL).
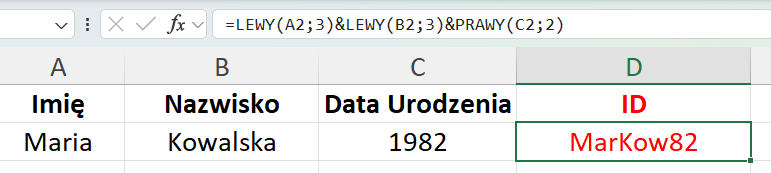
W praktyce organizacje pozarządowe często tworzą jednak własne systemy identyfikatorów, służące zarówno identyfikacji, jak i deduplikacji danych. Jedną z prostych i powszechnie stosowanych metod jest generowanie unikalnego kodu na podstawie wybranych danych osobowych, np. poprzez połączenie fragmentów imienia, nazwiska i roku urodzenia. Przykładowo, dla beneficjentki Marii Kowalskiej urodzonej w 1982 roku identyfikator może mieć postać „MarKow82”.
W programie Excel proces ten można zautomatyzować, wykorzystując funkcje takie jak LEWY i PRAWY, które pozwalają pobrać określoną liczbę znaków z wybranych komórek. Takie rozwiązanie zwiększa spójność danych, ogranicza ryzyko błędów ludzkich oraz ułatwia zarządzanie informacjami na większą skalę.
- Wykorzystanie unikalnych kodów do pobierania danych z różnych tabel
Unikalny kod umożliwia łatwe odwoływanie się do danych tego samego beneficjenta przechowywanych w różnych tabelach lub arkuszach. Dzięki temu, gdy uczestnik zapisuje się na wydarzenie lub konsultacje, nie ma potrzeby ponownego zbierania informacji, takich jak wiek czy status wrażliwości, jeśli zostały one już wcześniej zgromadzone podczas rejestracji do projektu. Wystarczy podać identyfikator i odszukać odpowiednie dane.
W programie Excel można to zrobić za pomocą funkcji X.WYSZUKAJ, która służy do wyszukiwania danych w tabelach. W praktyce łączy ona funkcjonalności znane z funkcji WYSZUKAJ.PIONOWO i WYSZUKAJ.POZIOMO, a dodatkowo oferuje lepszą obsługę błędów, co czyni ją bardziej elastycznym i niezawodnym narzędziem (obejrzyj filmik instruktażowy).
- Liczenie wieku I przypisanie do grupy wiekowej
Często zdarza się, że różni donatorzy stosują odmienne kategorie wiekowe – jeden może wymagać podania liczby dzieci w wieku 0–18 lat, podczas gdy inny oczekuje podziału na bardziej szczegółowe grupy, np. 0–5, 6–12, 13–17 lat. Sytuacja ta staje się szczególnie problematyczna w projektach finansowanych przez kilku darczyńców jednocześnie.
Praktycznym rozwiązaniem jest zbieranie daty urodzenia beneficjenta zamiast jego wieku. Pozwala to określać aktualny wiek na dowolnym etapie realizacji projektu, a nie tylko w momencie rejestracji. Następnie w programie Excel można wykorzystać funkcję DATA.RÓŻNICA, która umożliwia obliczenie różnicy między dwiema datami w latach, miesiącach lub dniach (obejrzyj filmik instruktażowy).
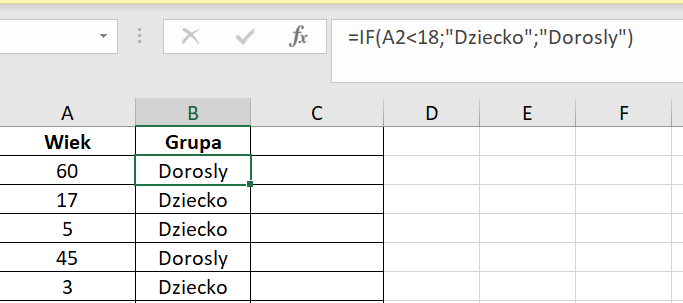
Następnie aby przypisać każdego uczestnika do odpowiedniej grupy wiekowej (np. „Dziecko” lub „Dorosły”), używamy funkcji JEŻELI. Na przykład, jeśli wartość wieku w komórce z wiekiem (A2) jest mniejsza niż 18, uczestnik jest klasyfikowany jako „Dziecko”; w przeciwnym razie jest klasyfikowany jako „Dorosły”. Używana formuła to =IF(A2<18;„Dziecko”;„Dorosły”).
Podsumowanie
Precyzyjne określenie liczby osób objętych wsparciem, oszacowanie liczby beneficjentów pośrednich oraz właściwe uporządkowanie i dezagregacja danych stanowią fundament podejmowania decyzji opartych na dowodach. Niezależnie od poziomu zaawansowania organizacji w zarządzaniu danymi, ważne jest także transparentne komunikowanie ograniczeń związanych z ich jakością i dostępnością.
Przykładowo, World Food Programme (WFP) stosuje zastrzeżenie, zgodnie z którym — ze względu na trudności w gromadzeniu i weryfikacji danych, eliminowaniu podwójnego liczenia oraz konieczność stosowania szacunków — ostateczną liczbę beneficjentów należy traktować jako możliwie najlepsze przybliżenie, a nie wartość dokładną (porównaj: WFP).
Takie podejście sprzyja jednocześnie rozwojowi systemów zarządzania danymi — w tym wzmacnianiu ochrony danych i standardów etycznych ich gromadzenia, a także integracji baz danych z bardziej zaawansowanymi narzędziami analitycznymi.
Artykuł powstał w ramach kampanii upowszechniającej organizacyjne uczenie się: Od-ucz się tego co już nie działa, czytaj więcej.
O autorce
Dr Hanna Kalyta – Konsultantka ds. monitorowania i ewaluacji (ME) z 17-letnim doświadczeniem, w tym 7 lat w dziedzinie rozwoju i 10 lat w projektach kryzysowych dla międzynarodowych organizacji pozarządowych (INGO). Ekspert w projektowaniu
systemów i narzędzi ME, zarządzaniu projektami, ekspert w zakresie oceny zdolności organizacyjnych. Posiada doświadczenie regionalne na Ukrainie, w Polsce, Rumunii, i Mołdawii jako Doradca z ME programy pomocy uchodźcom w HIAS. Była m.in. koordynatorką ds. monitoringu i ewaluacji w organizacji SOS Wioski Dziecięce w Ukrainie w latach 2020-2023 (pomoc kryzysowa dla przesiedlonych rodzin z dziećmi w 5 regionach Ukrainy), a także w organizacji ADRA na Ukrainie w latach 2015-2020 . Biegła w posługiwaniu się narzędziami M&E (Power BI, Power Query, Excel Pro, SPSS, JASP i KOBO). Członek Zarządu Ukraińskiego Towarzystwa Ewaluacyjnego i członek zespołów konsultingowych UE ds. ewaluacji.




